

佐思汽研数据显示,2024年1-9月,国内市场(不含进出口)乘用车前装标配智驾域控制器已达到225.4万套。2023年以来,自动驾驶域控渗透率逐月大幅上升,2024年9月自动驾驶域控渗透率已达到17.4%,而去年同期仅为8.61%。

各大主机厂的自动驾驶域控开发和应用已经基本普及,下一阶段主要是向中央计算机(CCU)发展演进。在本报告中,我们将自动驾驶域控制器的发展分为三个阶段:
采用多盒,每个域控制器单独一块电路板,各个域之间通过Ethernet传输数据,这是现阶段普遍采用的域集中式E/E架构,优势在于技术成熟,成本可控,劣势在于Ethernet传输速率有限,目前多为100-1000Mb/s级别。
车内不同域之间不再需要编码解码,省去了编码和解码的芯片电源、散热、线束,降低了成本,芯片通过PCIe接口传输数据,目前PCIe Gen 4广泛应用于汽车系统,Gen 4 具有 16 GT/s,每通道速率为 1.97 Gb/s,通过多通道聚合,传输速率远远高于Ethernet,一般可达到10Gb/s+。
这一阶段,多将车身域、网关等功能做集成,搭载以NXPS32G、芯驰 G9H 、瑞萨RH850等中央网关芯片。
整个域控制器 SoC 有多个 IP core(IP内核),IP核之间采用片间通信互联,未来的众多高性能电动汽车将搭载英伟达采用Blackwell架构的新一代自动驾驶汽车(AV)处理器DRIVE Thor,NVIDIA Blackwell 架构搭载专为Transformer、大语言模型(LLM)和生成式AI工作负载而打造,英伟达为下一代Thor配套了NVLink 5互联技术。芯片内存带宽可以达到100 Gb/s以上。
总结来看,第一阶段 multi board 方案已基本实现;领先的新势力车厂,如蔚来、小鹏等已进入第二阶段,实现量产交付 One board 方案,部分车厂可能选择直接过渡到第三大阶段 —— One Chip 方案,预计2025年将成为 One Chip 方案规模量产元年。在这一过程中,一般来说,底盘域、动力域不会随 One Chip 集成,主要是由于供应商解决方案较为封闭,向主机厂开放权限的可能性不大。
AI大模型作为主机厂竞争的焦点,One Chip 方案具备高带宽能力,能够让所有软件共享数据和算力,支持实现诸如端到端大模型、语言大模型等。
此外,One Chip 方案下,IP core(IP内核)自由组合成为可能,基于Chiplet架构设计的芯片将成为未来十年车载芯片发展的重要方向之一。

来源:佐思汽研《2024-2025年自动驾驶域控制器和中央计算机(CCU)行业研究报告》
自动驾驶域控开发策略——行业正快速部署 One board 、One chip 方案
进入2024年,迫于进一步降本的压力,行业正快速部署 One board 、One chip 智驾域控方案。
来源:佐思汽研《2024-2025年自动驾驶域控制器和中央计算机(CCU)行业研究报告》
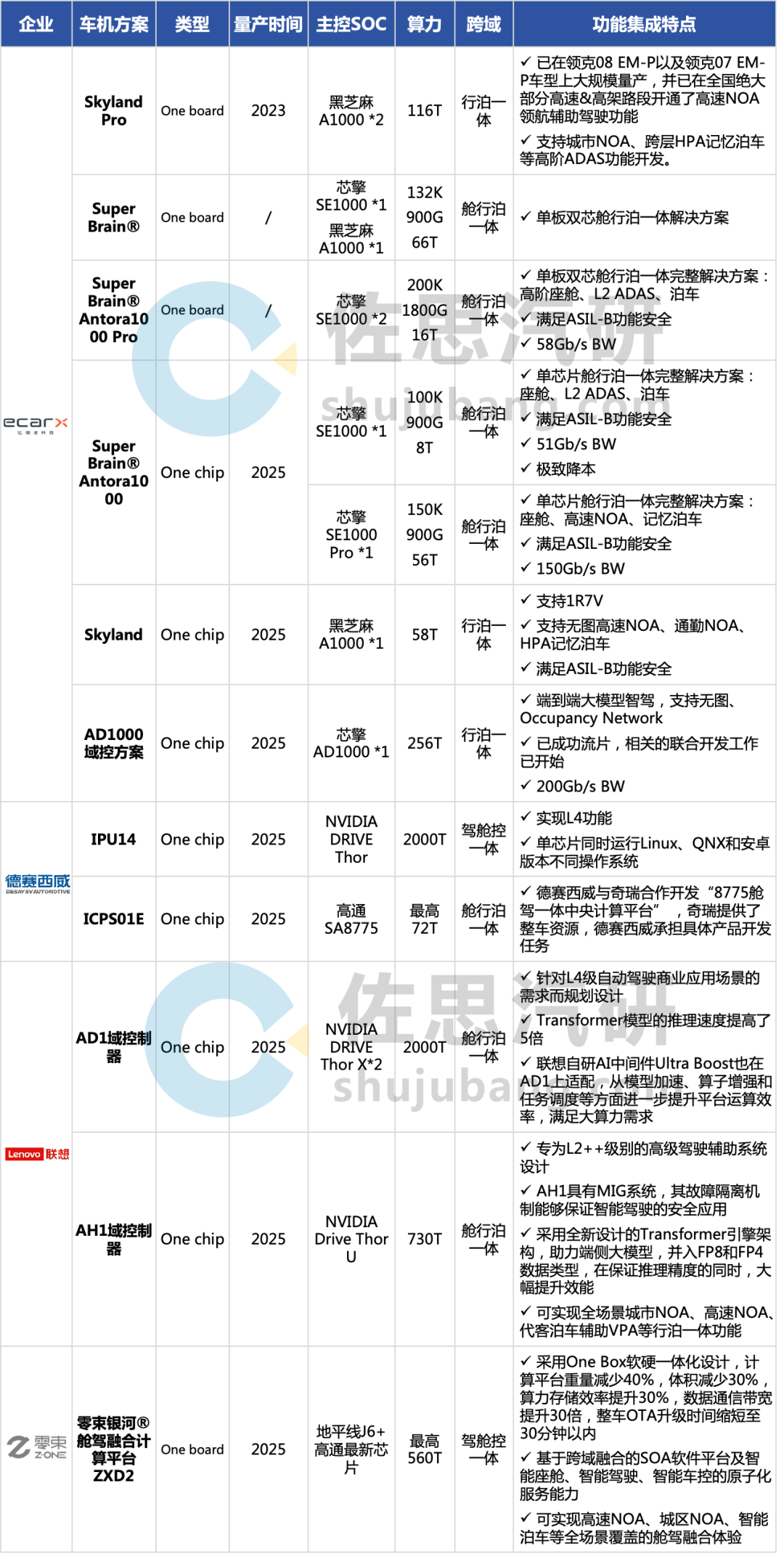
“One board”:亿咖通科技在“One Board”的方案设计上,主要围绕“可量产落地”的国芯策略,硬件方面采用了“单板双芯”的架构设计,芯片采用的是国内成熟的7nm车规级米乐 登录入口(龍鹰一号)、智驾SoC(华山A1000),两颗主控SoC通过PCIe实现高速互联;软件的部分,通过高度标准化、模块化的“云山”跨域软件平台,实现各个功能域的互联互通,从而实现第二阶段 “单板多芯(One Board)” 域控/中央计算平台量产落地。
其中,搭载两颗黑芝麻智能“华山A1000”芯片的亿咖通·天穹Pro 智能驾驶计算平台以及两颗“龍鹰一号”的亿咖通·安托拉1000 Pro计算平台已在领克08 EM-P以及领克07 EM-P车型上实现大规模量产交付。
“One Chip”:亿咖通科技目前基于国内首款7nm车规级SoC “龍鹰一号”(8 TOPS)打造了两款“舱泊一体”One Chip产品,分别为「亿咖通•安托拉1000计算平台AI加强版」以及「亿咖通•汽车大脑 安托拉1000Plus计算平台」,两款产品分别搭载于吉利银河E5、领克Z20车型上大规模量产,银河E5智能化口碑与市场表现俱佳,量产层面取得了良好的市场反馈。
而集成度更高的“舱行泊”一体版本,可支持包括L2ADAS、自动泊车、主流座舱功能在内的舱行泊一体功能开发,具备极高性价比,预计于2025年上车。据悉,未来亿咖通科技可能会基于升级后的“龍鹰一号Pro”(56 TOPS)开发舱行泊一体方案,支持更高阶的舱行泊一体功能。

来源:佐思汽研《2024-2025年自动驾驶域控制器和中央计算机(CCU)行业研究报告》
IPU14:2024年10月,德赛西威下一代高性能智能驾驶域控制器IPU14首次公开展示,搭载了英伟达最强智驾芯片Thor-U,支持单芯片驾舱控一体,并支持L3级有条件自动驾驶,还具备部分场景L4级自动驾驶的能力;
ICPS01E:2024年10月,德赛西威与奇瑞携手开发的“8775舱驾一体中央计算平台” 公开展出,在本次联合开发过程中,奇瑞提供了整车资源,德赛西威承担具体产品开发任务。

来源:佐思汽研《2024-2025年自动驾驶域控制器和中央计算机(CCU)行业研究报告》
2024年9月,基于地平线系列+座舱SoC打造的零束中央大脑二代ZXD2(Z-ONE X Device)首样顺利点亮;
ZXD2采用One Box软硬一体化设计,计算平台重量减少40%,体积减少30%,算力存储效率提升30%,数据通信带宽提升30倍,整车OTA升级时间缩短至30分钟以内。

主机厂层面,部分厂商已陆续实现了 “单板多芯(One Board)” 域控计算平台量产落地,包括小鹏汽车、蔚来汽车等。
实现了C-DCU、XPU二合一,实现智能驾驶、座舱、仪表、网关、IMU、功放等功能集成,相比上一代中央计算架构,XCCP实现了40%成本节约,性能提升50%;
小鹏X9实现了驾舱融合,同一块电路板上,两块芯片的通信是PCIe,速度能达到10个Gb/s级别;
舱驾融合方案,1颗高通骁龙8295智能座舱芯片+4颗英伟达Orin X智能驾驶芯片。新的中央计算平台集成器件数量12,000+,攻克了高集成度带来的PI/SI,EMC,Thermal等技术难题,相较于分离式舱驾域控制器体积减少40%,重量减轻20%;
中央计算平台ADAM可以让车内不同域之间不再需要编码解码,省去了编码和解码的芯片、电源、散热、线束等,通过电路板上的蚀刻电路直接取代千兆以太网,智驾和座舱之间跨域数据带宽从千兆大幅提升至16Gbps,实现10倍以上的传输速率提升;
跨域算力共享,调用智驾、智舱和整车控制最大256TOPS算力;同时,跨域算力共享还可以更合理分配各个大算力需求,而非完全限制在各自的智驾、智舱领域。
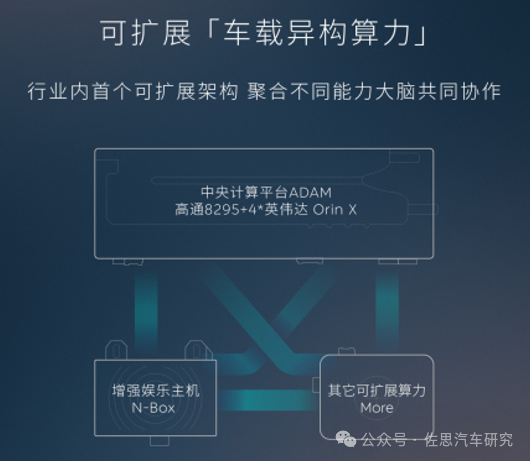
系统响应更快:相对于板间的Switch通讯或芯片间PCIe通信,片内通信延迟更短,带宽更大,系统响应更快
软件共享数据和算力:统一的整车级操作系统,支持实现诸如端到端大模型、语言大模型等
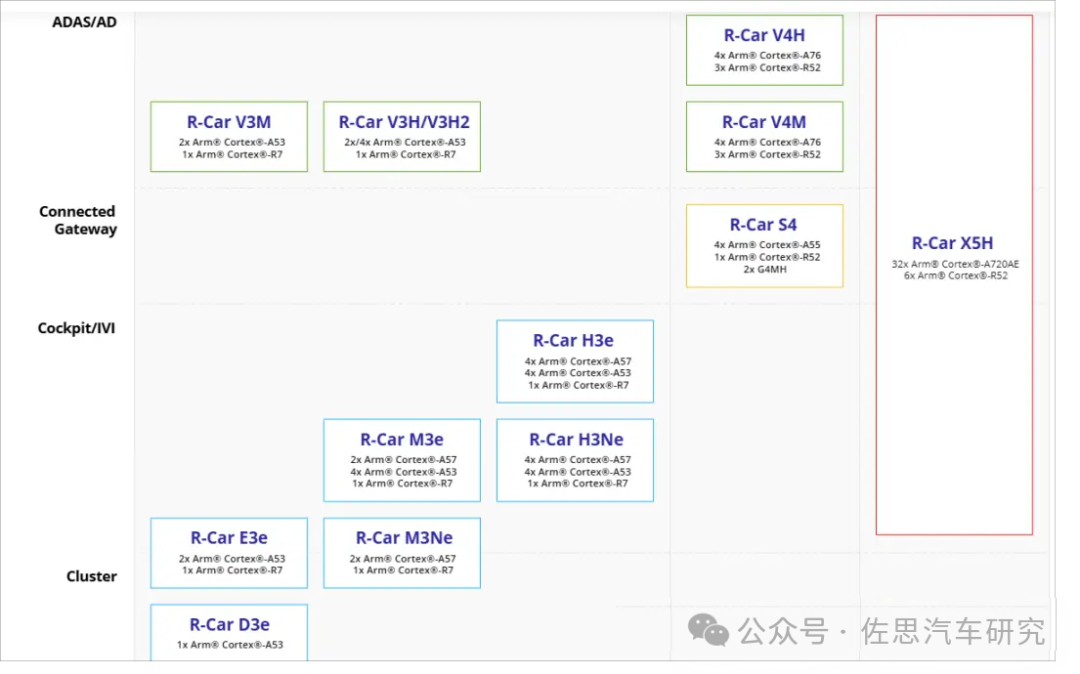
2024年11月,瑞萨在业内率先推出采用车规3nm制程的多域融合SoC——R-Car X5系列,单个芯片可同时支持多个汽车功能域,包括高级驾驶辅助系统(ADAS)、车载信息娱乐系统(IVI)以及网关应用在内的多个车载应用。该SoC还提供通过Chiplet(小芯片封装)技术扩展人工智能(AI)和图形处理性能的选项。R-Car X5系列计划于2027年量产。
3nm工艺,采用台积电最先进的工艺节点制造,同等性能下,功耗比5nm工艺节点设计的产品降低30-35%
400TOPS AI算力,支持通过Chiplet扩展,可以将AI处理性能提升3-4倍甚至更多
采用Chiplet技术,提供标准的UCle(通用小芯片互联通道)芯片间互联接口及API
可以预见,One Chip 方案将对汽车域控制器硬件、整车操作系统、车规SoC设计和制造等产业链带来深远影响。主机厂、Tier1和芯片厂商,将围绕多域融合、chiplet芯粒、片间互联(如PCIe、NVLink等)等新技术领域展开激烈竞争。
原文标题:自动驾驶域控研究:One board/One Chip方案将对汽车供应链产生深远影响
文章出处:【微信号:zuosiqiche,微信公众号:佐思汽车研究】欢迎添加关注!文章转载请注明出处。
安全吗? /
模式,不仅提高了道路交通的安全性和效率,还有望改变人们的出行方式,对城市交通
FPGA(Field-Programmable Gate Array,现场可编程门阵列)在
低,适合用于实现高效的图像算法,如车道线检测、交通标志识别等。 雷达和LiDAR处理:
通常会使用雷达和LiDAR(激光雷达)等多种传感器来获取环境信息。FPGA能够协助完成这些传感器
7月8日,三星电子公司遭遇了其成立55年以来的最大规模罢工事件,数千名电子部门的工人计划展开为期三天的罢工行动,以抗议薪资问题。这一前所未有的罢工行动不仅震撼了韩国科技界,更可能对全球芯片
生态伙伴奖” /
全球独立的线控制动厂家只有博世、大陆和ZF TRW三家,L3/L4的线控制动
进迭时空 K1 系列 8 核 64 位 RISC - V AI CPU 芯片介绍
联系我们
18081662636 联系人:王先生 传真:023-67660436 |
